Performance
Benchmarks
The RAPTOR engine is designed for speed: all GTFS data is held in memory with optimized data structures.
Benchmark across 12 origin/destination pairs covering Ile-de-France (10 rounds, single-threaded):
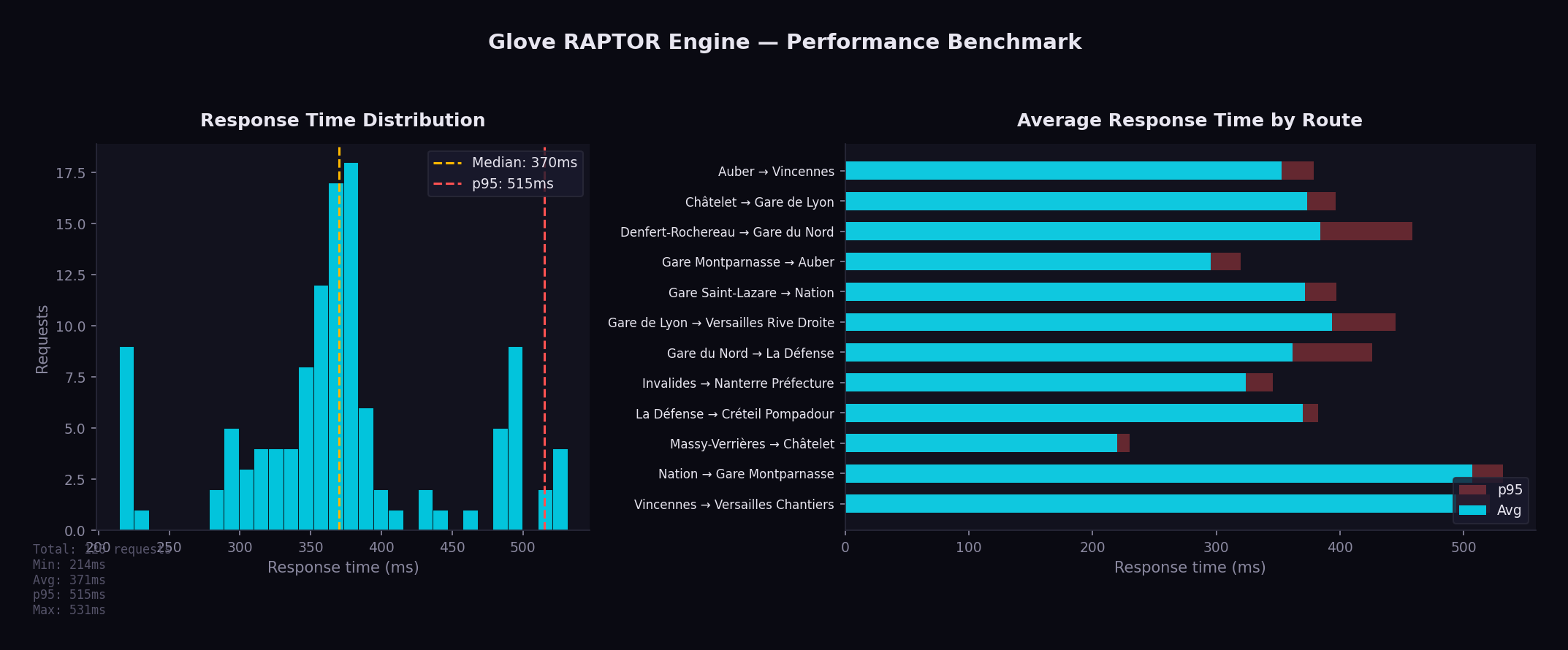
| Metric | Value |
|---|---|
| Min | 215 ms |
| Avg | 371 ms |
| Median | 370 ms |
| p95 | 515 ms |
| Max | 531 ms |
Running Benchmarks
python3 bin/benchmark.py --rounds 10 --concurrency 1
The benchmark script:
- Sends requests to 12 representative origin/destination pairs
- Measures response times across multiple rounds
- Generates a chart with statistics
Key Optimizations
Binary Search in Trip Lookup
The find_earliest_trip function uses binary search (O(log n)) to find the first trip departing after a given time within a pattern, instead of linear scan.
Pre-Allocated Buffers
Label arrays and working buffers are allocated once and reused across RAPTOR rounds, eliminating per-round allocation overhead.
FxHashMap
Uses rustc-hash's FxHashMap throughout both GtfsData and RaptorData, replacing all standard library HashMap instances. FxHash is significantly faster than the default SipHash for integer and string keys.
Lock-Free Hot-Reload
ArcSwap provides atomic pointer swaps with zero contention. Readers never block, even during a reload. There is no mutex, no RwLock, and no read-side overhead.
Early Termination in Diversity Loop
The RAPTOR diversity loop (which re-runs the algorithm with pattern exclusion to find alternative journeys) now terminates early when a round produces no new journeys, avoiding unnecessary iterations.
Arc<WalkLeg> Cache
Walking leg results from Valhalla are wrapped in Arc<WalkLeg> and cached, avoiding deep cloning of polyline coordinates when the same walk leg is referenced by multiple journeys.
Batch Valhalla Calls
Transfer enrichment requests to Valhalla are dispatched in parallel using futures::join_all, rather than sequentially, significantly reducing latency for journeys with multiple transfers.
Pareto-Optimal Exploitation
All Pareto-optimal journeys from a single RAPTOR run are collected before the algorithm is re-run with pattern exclusion. This avoids redundant computation.
Cache Persistence
The RAPTOR index is serialized to disk with a fingerprint derived from the GTFS data. On restart, if the fingerprint matches, the cached index is loaded in sub-second time instead of rebuilding (10-30 seconds).
Pattern Grouping
Trips with identical stop sequences share a single pattern. For a typical Ile-de-France dataset, this reduces the number of entities the algorithm scans by an order of magnitude.
Memory Usage
All GTFS data is held in memory. For the Ile-de-France dataset:
| Data | Approximate Size |
|---|---|
| Stops | ~48,000 entries |
| Trips | ~320,000 entries |
| Stop times | ~8,500,000 entries |
| Patterns | ~15,000 groups |
| Total RAM | ~500 MB |